Спасибо ответившим!
Вобщем, я пока склоняюсь к следующему частному компромисному решению...
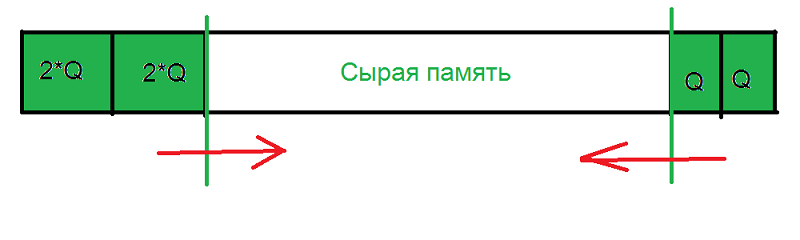
Заранее небольшое количество памяти нарезается для 64-байтных объектов, вся остальная память нарезается под 128-байтные объекты.
Все объекты помещаются в два односвязных списка свободных элементов (64 и 128 байтных). Списки организуются на памяти самих же свободных объектов.
Когда запрашивается 64 байта, тогда выдаётся элемент из списка 64-байтных, а когда этот список становится пустым, то, скрипя зубами, выдаётся, отрывается от сердца, элемент из списка 128 байтных блоков.
Как то так (число 48Mb взято просто для примера):
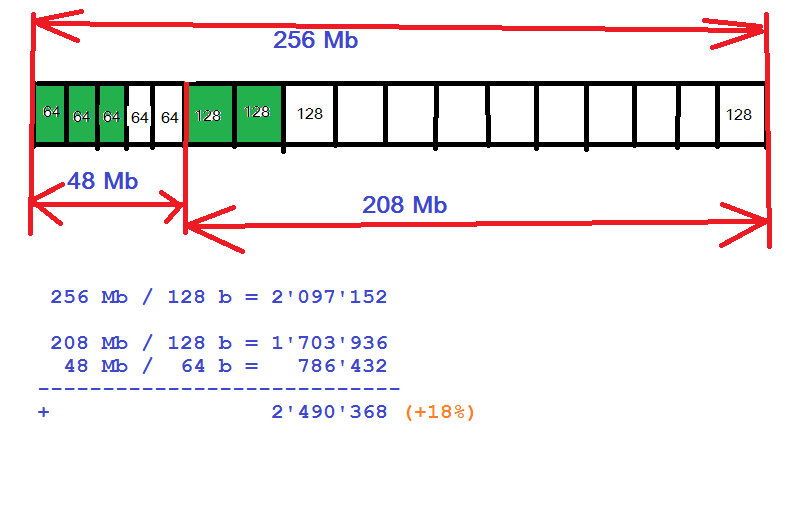
Когда указатель на 64 байтный объект возвращается, то одной проверкой if (p < 48Mb) выясняется кто он на самом деле: истинный 64 байтный или 128 байтовый. Соответственно, ставится в список свободных 64 или 128 байтных блоков.
Оптимальный размер памяти отдаваемый под 64 байтные объекты надо будет выяснить экспериментально.
Почему так, а не иначе:
1) Есть жёсткое ограничение на количество обращений к DDR3 памяти (пропускная способность контроллера памяти является "бутылочным горлышком" для нашего программного продукта).
2) Аллокация/деаллокация 64 байтных блоков происходит на порядок чаще чем 128 байтных.
Поэтому приходится отказываться от алгоритмов делающих слияние свободных блоков 64+64=128.
Если кто нибудь придумает как ещё больше сэкономить память не слишком сильно замедляя алгоритм, то это будет круто...